知識型AI
v4.65でアップデート
備考
・接続先の生成AIモデルプロバイダーの規約に従うものとします。第三者のサービス、システム、または資料の使用について、Cognigyは一切の責任を負いません。
・Cognigyの既存カスタマーである場合、知識型AIのトライアル版には、契約で指定されたパフォーマンスタイムライン(SLA)は適用されません。
知識型AIは、自然言語処理(NLP)や対話型AIを強化するために使用することができます。知識型AIの主な目的は、これらのシステムが、文書、記事、マニュアル、FAQなど、さまざまな形式から膨大な量の情報にアクセスし、理解できるようにすることです。知識ベースにアクセスし理解することで、これらのAIシステムは、ユーザーのクエリに対して、より正確で、コンテキストを認識した、有益な回答を提供することができます。
Cognigy知識型AIソリューションを使用すると、ユーザーの質問を特定し、事前に定義された回答に基づいて適切なコンテンツを提供するために、IntentsとDefault Repliesだけに頼る必要がなくなります。このような質問と回答のペアを作成するには時間と労力がかかり、継続的なメンテナンスが必要になります。
その代わりに、Cognigy知識型AIでは、既存の知識をPDF、テキスト、DOCXファイル、Cognigy CTXT形式のファイルなどのドキュメントとしてアップロードできます。このテクノロジーは、これらのドキュメントから意味のある情報を抽出し、Knowledge AI Nodesを通じてFlowデザイナーがアクセスできるようにします。このアプローチにより、知識ベースのバーチャルエージェントを迅速かつ容易に構築することができ、従来のインテント型システムの制限を回避し、洗練されたトーク体験価値の作成プロセスをシンプルにすることができます。
前提条件
この機能を使用する前に、いずれかのLLMプロバイダーでアカウントを作成してください:
- OpenAI。有料アカウントを持っているか、アクセスを提供する組織のメンバーである必要があります。OpenAIのユーザープロファイルを開き、既存のAPIキーをコピーするか、新しいAPIキーを作成してコピーする。
- Microsoft Azure OpenAI。有料アカウントを持っているか、アクセスを提供する組織のメンバーである必要があります。Azure管理者にAPIキー、リソース名、デプロイメントモデルをご確認ください。
知識型AI のケースでは、text-embedding-ada-002 モデルが必要です。ただし、Knowledge Searchの結果を変換して出力する場合は、サポートされるモデルリストの [LLM Prompt Node & Search Extract Output Node] 列にある追加モデルも必要です。
Knowledge Storeの作成
構成済みのKnowledge Storeを作成することができます。そのためには、以下の手順で行います:
1. Cognigy.AIインタフェースを開きます。
2. 左側のメニューで[Knowledge]を選択します。knowledgeウィザードが開きます。
3. ウィザードの指示に従います。
4. 一意の名前を指定し、埋め込みモデルを選択します。
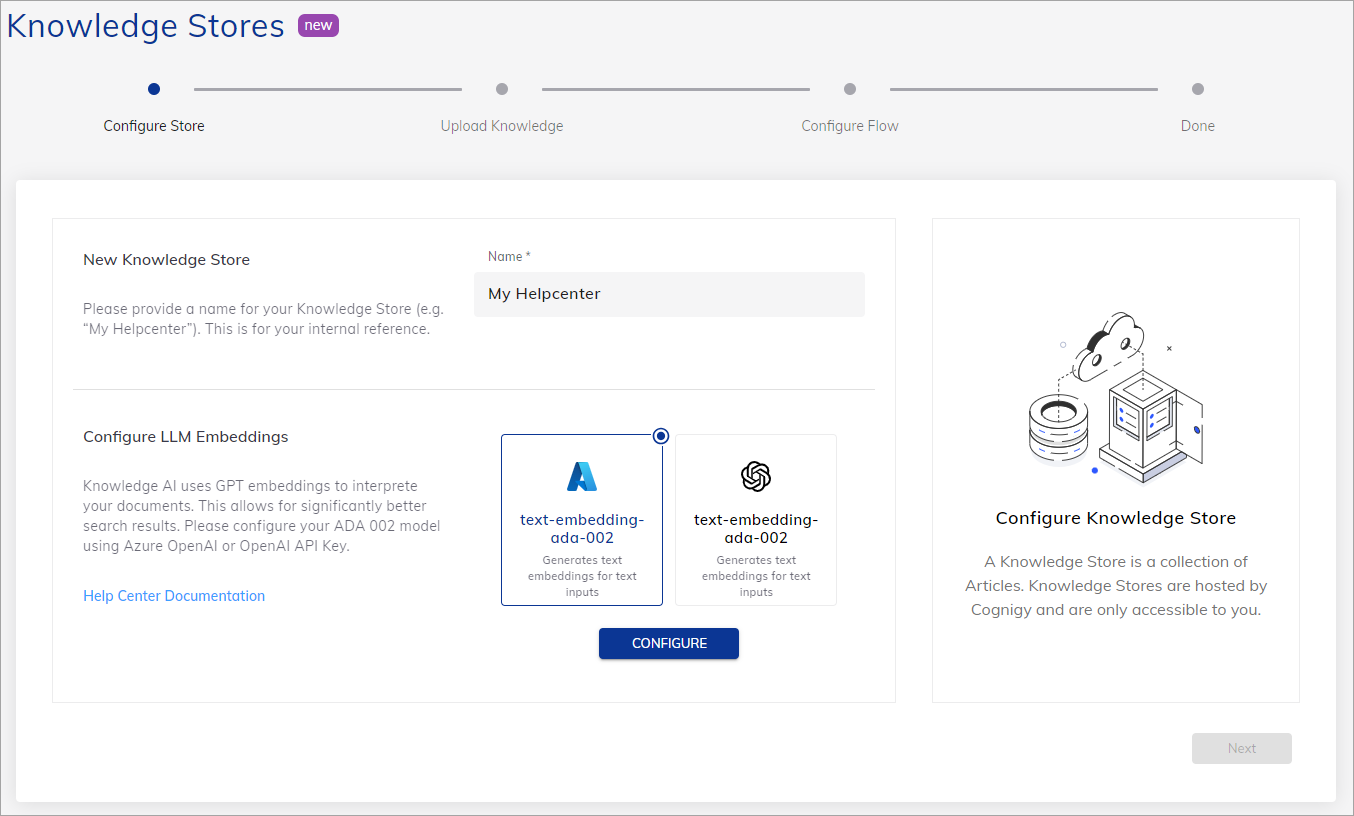
5. [Configure]をクリックし、モデルの認証情報を入力します:
- Microsoft Azure OpenAI
- OpenAI
- 接続名 – 一意の接続名を作成します。
- apiキー – Azure APIキーを追加します。この値は、Azureポータルからリソースを調べる際に、Keys & Endpointセクションで確認できます。
KEY1またはKEY2のいずれかを使用できます。 - リソース名 – リソース名を追加します。この値は、Azure ポータルの[Resource Management] > [Deployments] か、Azure OpenAI Studio の [Management] > [Deployments]にあります。
- デプロイメント名 – モデル名を追加します。
- API バージョン – API のバージョンを追加します。この操作に使用する API バージョンを
YYYY-MM-DD形式で指定します。バージョンは、例えば2023-03-15-previewのように、拡張された形式になることにご留意ください。 - カスタムURL – このパラメータはオプションです。クラスタと Azure OpenAI プロバイダ間の接続を制御するために、専用のプロキシサーバを経由して接続をルーティングし、追加のセキュリティレイヤーを作成することができます。これを行うには、次のパターンで URL を指定します:
https://カスタムURLが追加されると、リソース名、デプロイメント名、および APIバージョンのフィールドは無視されます。.openai.azure.com/openai/deployments/ /completions?api-version=
- 接続名 – 一意の接続名を作成します。
- APIキー – OpenAI アカウントAPIキーを追加します。このキーは OpenAI アカウントの[User settings]にあります。
- カスタムモデル – このパラメータはオプションです。使いたいモデルを追加します。このパラメータは、LLM プロバイダ側に複数のタイプのモデルがあり、特定のモデルタイプを利用する場合に役立ちます。例えば、GPT-4を持っている場合、使用例に
gpt-4-0613を指定することができます。カスタムモデルが追加された場合、デフォルトのLLMモデルは無視されます。プロバイダのモデルの詳細については、 [OpenAI]のドキュメントをご参照ください。
6. [Next]をクリックする。
7. .ctxt形式のcognigy-sample.ctxtファイルをダウンロードします。
8. Upload Knowledgeステップで、Cognigy CTXTタイプを選択し、保存したファイルをアップロードし、[Next]をクリックします。knowledgeソースはファイル名と同じ名前になります。ステップ7で説明したファイルとは別のファイルをアップロードする場合は、ファイル名の長さは最大200記号で、先頭または末尾にスペースを使用せず、以下の文字を含めることはできません: / \ : * ? " < > | ¥
9. (オプション) [Configure Answer Extraction Model] セクションで、キーポイントを抽出し、検索結果をテキストまたは適応カードとして出力する場合は、追加モデルを選択します。[Configure]をクリックし、モデルの認証情報を入力します。
10. (オプション)追加モデルの設定が完了したら、[Create Flow]をクリックします。Search Extract Output Nodeを持つFlowが作成されます。
11. [Next] をクリックします。
ctxtの詳細については、[Cognigy Text Format]をご参照ください。
知識型AIのプロジェクトのエクスプローラー
知識型AIの作業には、Intentsの作業と同様に2つのフェーズがあります。最初のフェーズは知識の取り込みと準備、2番目のフェーズは実行時に知識を照会することです。
最初のフェーズ:
- 未加工情報のアップロード。Cognigy.AIは、知識を含むアップロードされたファイルを通じて未加工情報にアクセスします。
- 知識チャンクの抽出。未加工の情報からテキストとメタデータを抽出するツールのコレクション。チャンクはチャンクエディターで変更可能です。
- ベクトル化。知識チャンクのテキストは、埋め込み機械学習モデルを使用して数値表現にエンコードされます。埋め込みは、単語の意味と類似性を数値表現にエンコードする高次元ベクトルです。Cognigy.AIはこれらのベクトルを専用の内部データベースに保存し、実行時に素早くアクセスできるようにします。
2番目のフェーズ:
- 知識ベースのクエリ。実行中、知識型AIシステムは知識ベースを照会し、ユーザーのクエリに対して正確で文脈に応じた適切な応答を提供することができます。
- 知識ベースのバーチャルエージェントの構築。バーチャルエージェントは、知識ベースに格納された知識を利用し、より洗練され知性を持ったトークをユーザーと行います。これらのエージェントは、アップロードされたファイルから抽出された情報に基づいて、文脈を考慮した応答を提供することができます。
知識型AI管理
知識は、システムによる正確な応答を可能にするために、ストア、ソース、チャンクの階層構造で整理されます。これらの階層構造を以下に説明します。
Knowledge Store(知識ストア)
Knowledge Storeは、複数の知識ソースを保持し、整理するコンテナです。さまざまな知識ソースを一元管理し、分類するための構造化された環境を提供します。Knowledge Storeは、関連するナレッジソースをグループ化し、実行時に関連情報の整理、検索、取得をより簡単にすることで、知識管理プロセスの合理化に役立ちます。
1プロジェクトあたりの最大ストア数は、[Limitations]のセクションに記載されています。

Knowledge Source(知識ソース)
Knowledge Sourceは、様々なタイプのファイルを構造化し、アクセス可能な形式に変換した出力を表します。各ファイルは、ユーザーマニュアル、記事、FAQ、およびその他の関連情報の形で有益な知識を含む、特定の知識ソースに一意に対応します。
これらのファイルのコンテンツをチャンクと呼ばれる小さな単位に分解することで、知識ソースは、組織化され構造化された知識の特定のコレクションになります。
主なコンテンツに加えて、リンクや日付などの他のタイプの情報をメタデータに含めることができます。
次の種類のファイルがサポートされています:
.ctxt(推奨).txt.pdf.docx
.ctxt(Cognigyテキスト)形式は、テキストを効果的にチャンクに分割し、メタデータを扱うための幅広い可能性を提供します。他のフォーマットでは、ファイル変換の結果が劣ることがあります。
.pdfフォーマットには2つのチャンク分割戦略があります。
1ストアあたりのソースの最大数については、[Limitations]セクションで説明しています。

さらに、Source Tags(ソースタグ)を使用することもできます。これらのタグは、知識検索の範囲を絞り込み、知識ベースの最も適切なセクションのみを含めることを可能にし、その結果、検索出力の精度を向上させます。
これらのタグを適用するには、ソースファイルをアップロードするときに指定します。.ctxt形式の場合はソースのメタデータに含める必要があります。その他の形式の場合は、新しい知識ソースを作成する際にCognigy.AIインタフェース内で指定する必要があります。
Source Tags(ソースタグ)
・1知識ソースあたりのタグ最大数は 10です。
・ソース作成後にソースタグを変更することはできません。
・既存のソースにソースタグを追加することはできません。
Chunk(チャンク)
チャンクとは、知識ソースから抽出された知識の単位です。チャンクとは、知識型AIシステムが効率的に処理・管理できる、自己完結した小さな情報の断片のことです。
例えば、チャンクは1つのパラグラフ、1つのセンテンス、またはドキュメントからのテキストの小さな単位を表すことができます。コンテンツをチャンクに分割することで、システムの粒度が向上し、ユーザーのクエリをより効率的に分析して応答できるようになります。知識をチャンクに抽出することで、ユーザーの質問に適切な情報をマッチさせるシステムの能力が向上し、より正確で文脈に応じた適切な応答が可能になります。
各チャンクは関連するメタデータを持つことができます。メタデータのキーと値のペアの数には制限があり、数値、文字列、ブーリアン型などの単純なデータ型のみをサポートします。チャンクの最大数と、チャンクごとにサポートされる文字の最大長については、[Limitations]のセクションで説明しています。

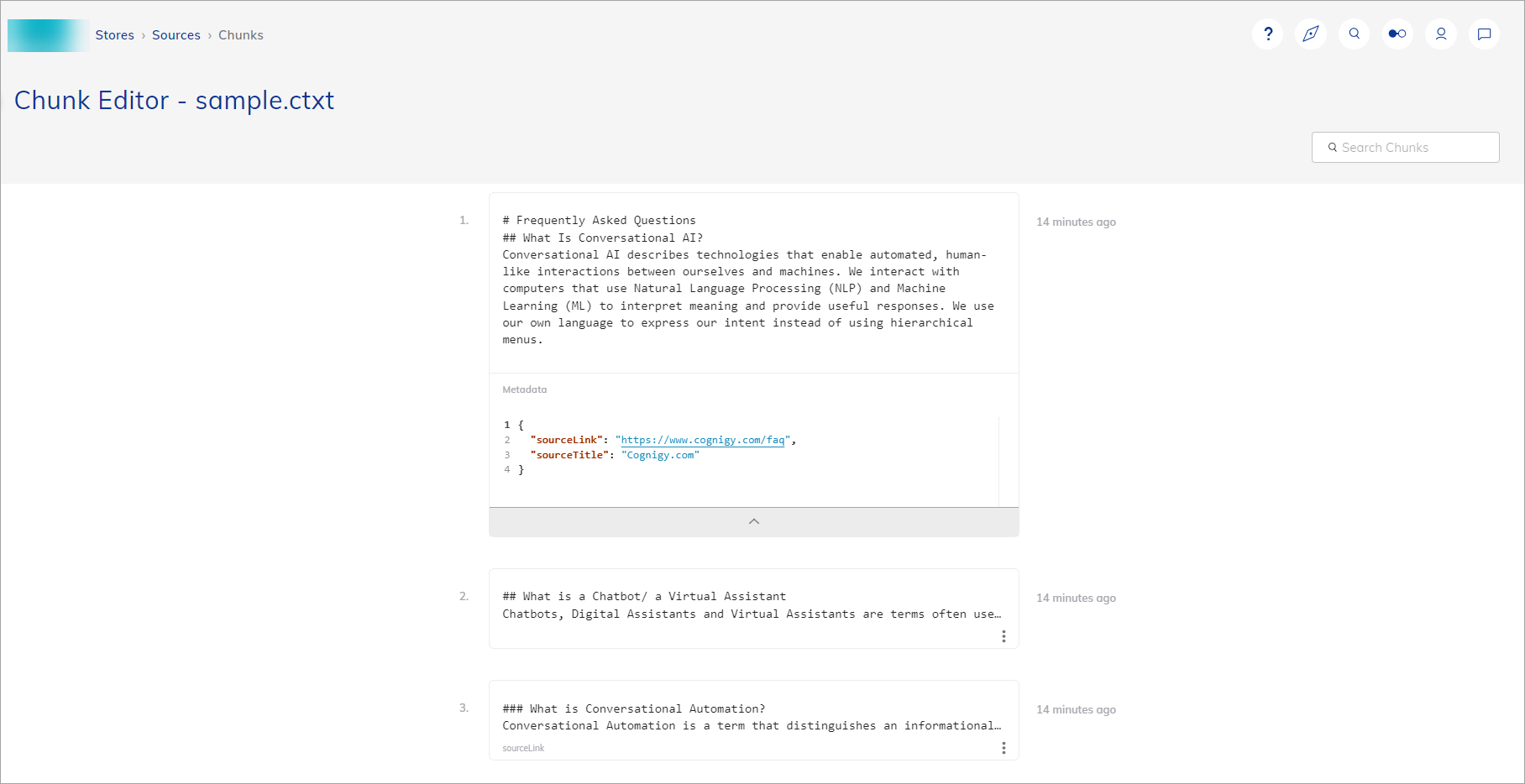
チャンクエディター
チャンクエディターは、チャンクを操作・管理するためのツールです。エディターは、各チャンク内のコンテンツを操作できる使いやすいインタフェースを提供します。ユーザーはテキストを修正したり、新しい情報を追加したり、セクションを削除したり、コンテンツの順序を並べ替えたりして、知識の正確性と関連性を確保することができます。
知識の検索、抽出、出力
1. [Build] > [Flows]に移動し、新しいFlowを作成します。
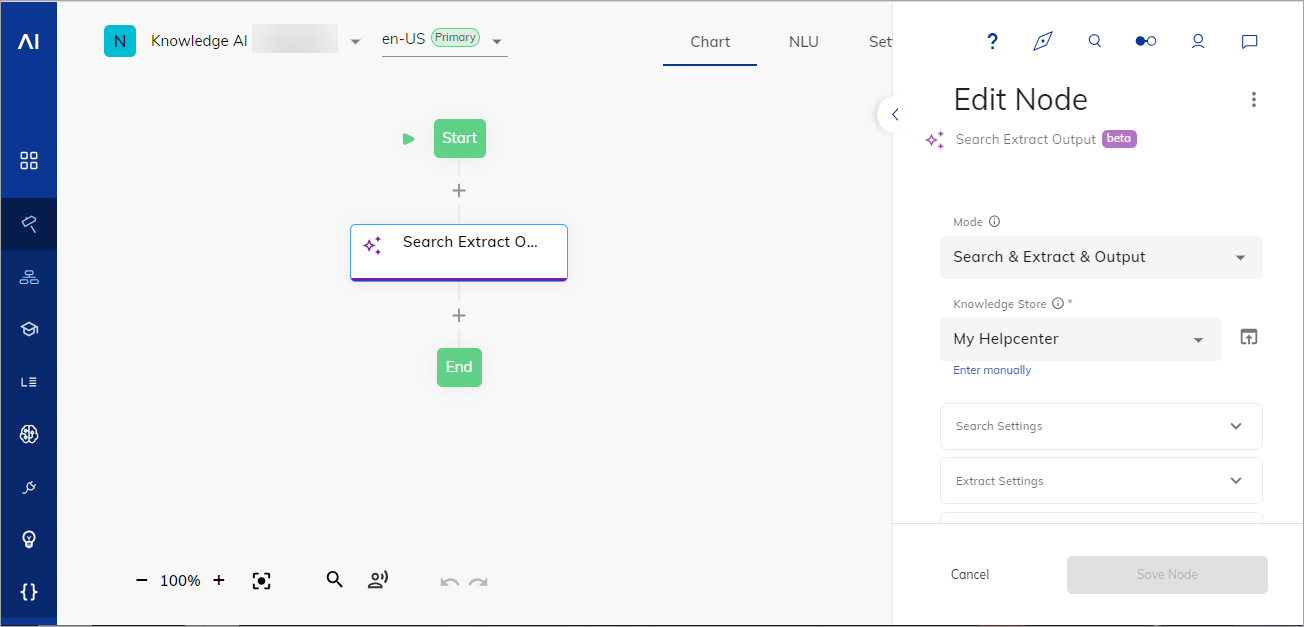
2. Flowエディターで、Search Extract Output Nodeを追加します。
3. Node エディターで、最近作成した知識ストアを選択します。
4. 以下のいずれかのモードを選択します:
- 検索&抽出&出力 – 知識検索を実行し、キーポイントを抽出し、結果をテキストまたはアダプティブカードとして出力します。このモードでは、
LLM Prompt Node & Search Extract Output NodeとKnowledge Searchの両方のケースをカバーする、対応プロバイダのリストのモデルが必要です。 - 検索&抽出 – 知識検索を行い、キーポイントを抽出しますが、自動出力は行いません。このモードでは、
LLM Prompt Node & Search Extract Output NodeとKnowledge Searchの両方のケースをカバーする、対応プロバイダリストのモデルが必要です。 - 検索のみ – 知識検索を行い、抽出や自動出力を行わずに情報を取得します。このモードでは、
text-embedding-ada-002モデルのみを使用します。
5. [Search settings(検索設定)]セクションで、[Context-Aware Search(コンテクストを考慮した検索)]が有効になっているかどうかを確認します。この機能は、トランスクリプトのコンテキストを考慮して検索し、バーチャルエージェントがフォローアップの質問に対応できるようにします。この機能は、LLM プローバー側で LLM トークンを消費することに注意してください。
6. [Context-Aware Search(コンテクストを考慮した検索)]設定が有効になっている場合は、[Transcript Steps]の数を設定します。この設定は、検索結果を取得するときに考慮されるコンテキストの深さに影響します。
7. (オプション) [Source Tags] フィールドで、各タグを個別に指定し、Enter キーを押してタグを追加します。タグを指定する前に、選択した知識ソースのソースファイルのアップロード時にタグが提供されていることを確認します。
8. [Save Node(ノードの保存)] をクリックします。
9. インタラクションパネルに進み、「Can Cognigy connect to a Contact Center?(Cognigyはコンタクトセンターに接続できますか?)」という質問を送信します。
学習された知識から生成された回答を受け取ります。
[Search Extract Output Node]の詳細については、関連記事をご参照ください。
制限事項
以下の表は制限事項を示しています。これらの制限はCognigyにより今後変更される場合があります。
| 説明 | 現行制限 |
| 1プロジェクトあたりの知識ストアの最大数 | 10 |
| 1ストアあたりの知識ソースの最大数 | 10 |
| 知識ソースを作成する際の最大ファイルアップロードサイズ | 10 MB |
| 1知識ソースあたりのソースタグの最大数 | 10 |
| 1Search Extract Output Nodeあたりのソースタグの最大数 | 5 |
| 1知識ソースあたりの最大チャンク数 | 1000 |
| ソースメタデータの最大ペア数 | 20 |
| チャンクメタデータの最大ペア数 | 20 |
| 1チャンクあたりのテキストの最大文字数 | 2000 |
| 1チャンクあたりのメタデータの最大文字数 | 1000 |
| 1ソースあたりのメタデータの最大文字数 | 1000 |
Snapshots
ストア、ソース、チャンクなどの知識型AI固有のオブジェクトは、Cognigy.AI Snapshotsの一部ではありません。この機能は近日中に実装される予定です
よくある質問
Q1: Knowledge AIは無償ですか?
A1: いいえ、近日中に価格情報を提供する予定です。
Q2: ファイルをアップロードしようとしたところ、「Request failed with status code 429」 というエラーが発生しました。どうすれば解決できますか?
A2: 429エラーは、LLMのプロバイダー側で組織の料金制限を超えた場合に発生します。詳しくは、プロバイダーのドキュメントをご参照ください。例えば、OpenAI APIを使用している場合、[429: ‘Too Many Requests’ エラーを解決するには?]をご覧ください。