Cognigy NLU: V1からV2へ
v4.60で追加
このガイドは、Cognigy NLPの旧バージョンから新バージョンに移行するCognigyオンプレミスのお客様を対象としています。
Cognigy NLU V1の廃止について
リリース4.60.0以降、旧NLPサービスのバグ修正は重要な場合のみ提供します。旧NLPサービスはリリース4.64.0で完全に非推奨となり、その時点ですべてのオンプレミスのお客様は移行しているはずです。4.64.0リリース後、古いNLPサービスは利用できなくなります。
はじめに
NLPサービスのスケーラビリティ、信頼性、セキュリティを向上させ、大規模なワークロードを処理し、ハードウェアのフットプリントを削減しました。その際、既存のNLP構造を複数の小さなサービスに分割し、独立したスケーラビリティを向上させました。さらに、学習済みNLUモデルの保存方法を調整し、モデルの学習時にサービスが必要とするメモリを削減しました。この変更により、システム上でモデルを再構築する必要があります。手作業でモデルを再構築するには多大な労力がかかるため、それを行う移行ジョブを作成しました。このガイドでは、移行ジョブの使い方を説明します。
Cognigyがホストするすべてのお客様の本番環境において、古いNLPサービスの移行と削除を正常に完了しました。
用語解説
このガイドでは特定の用語を使用しています。
旧NLPサービス
非推奨のNLPサービスを指します。
NLP V2スタック
当社が導入した新しいNLPサービスを指します。
最新情報
機能の変更
これらの変更は、既存のAIエージェントの機能には影響しません。機能的な変更は一切行っていないため、すべてのインテントモデルは現在と同じように機能し続けます。
これを確実にするため、何千ものリクエストを調査し、新旧のNLPサービス間でインテント結果を比較しました。その結果、リクエストの1%未満で、インテントのスコアに変化があることがわかりました。そのわずかなケースでも、インテントスコアの変化はごくわずかでした。
サービス構造の変更
以下のサービスが廃止されます:
service-nlp-score-<language>service-nlp-train-<language>
代わりに、以下のサービスが導入されます:
service-nlp-orchestratorservice-nlp-classifier-score-<language>service-nlp-classifier-train-<language>service-nlp-embedding-<language>
新サービスは旧サービスより小さくなり、スコアリングと学習の間や、異なる言語間でコンポーネントをよりうまく再利用できるようになりました。また、新しい構造では、環境の負荷が増加した場合に、より柔軟な調整が可能です。
移行品質保証
CognigyチームはCognigy.AIのリリース4.54.0で新しいNLPサービスのデプロイを開始しました。その結果、すでにこれらのサービスを本番環境で実行し、既存のAIエージェントを移行して新しいサービスを利用し、十分な経験を積んでいます。
さらに、Cognigyがホストしているすべてのお客様の環境を、停止時間やユーザーに影響を与えることなく移行することに成功しました。
開発環境と本番環境の移行
開発環境と本番環境など、Cognigy.AIを実行している複数の環境がある場合、すべての環境に同時にNLP V2を導入することが重要です。これにより、Snapshotsがこれらの環境間で転送されたときにスムーズに機能するようになります。
前提条件
移行を開始する前に、以下の前提条件が満たされていることを確認してください:
- Cognigy.AI バージョン 4.54.0 以上をデプロイする。
- すべての環境に NLP V2 スタックをデプロイする(下記参照)。
NLP V2スタックのインストール
NLP V2の有効化
NLP V2スタックを有効にするには、cognigyEnv config mapに環境変数を設定し、いくつかの新しいサービスをデプロイする必要があります。
cognigyEnv config mapで設定する必要がある環境変数は以下の通りです:
cognigyEnv:
FEATURE_USE_SERVICE_NLP_V2: "true"
FEATURE_MIGRATE_SNAPSHOTS_TO_NLP_V2: "true"これらの環境変数を設定しても、既存のモデルには影響しません。ただし、NLUモデルを再学習するとすぐに、NLP v2スタックを使用して学習します。
NLP V2サービスの追加
新しいNLP V2スタックには以下のサービスが含まれます:
service-nlp-orchestratorservice-nlp-embedding-<language>service-nlp-classifier-score-<language>service-nlp-classifier-train-<language>
この例に従って、values-local.yamlファイルにこれらのサービスを追加する必要があります:
serviceNlpOrchestrator:
enabled: true
replicaCount: 3
serviceNlpEmbeddingEn:
enabled: true
replicaCount: 3
serviceNlpEmbeddingXx:
enabled: true
replicaCount: 3
serviceNlpEmbeddingGe:
enabled: true
replicaCount: 2
serviceNlpClassifierScoreEn:
enabled: true
replicaCount: 3
serviceNlpClassifierTrainEn:
enabled: true
replicaCount: 3
serviceNlpClassifierScoreDe:
enabled: true
replicaCount: 3
serviceNlpClassifierTrainDe:
enabled: true
replicaCount: 3
serviceNlpClassifierScoreXx:
enabled: true
replicaCount: 3
serviceNlpClassifierTrainXx:
enabled: true
replicaCount: 3
serviceNlpClassifierScoreGe:
enabled: true
replicaCount: 3
serviceNlpClassifierTrainGe:
enabled: true
replicaCount: 3
serviceNlpClassifierScoreJa:
enabled: true
replicaCount: 3
serviceNlpClassifierTrainJa:
enabled: true
replicaCount: 3
serviceNlpClassifierScoreKo:
enabled: true
replicaCount: 3
serviceNlpClassifierTrainKo:
enabled: true
replicaCount: 3これらの変更をすべてのCognigy.AI環境に適用してください。
デプロイする言語の選択
NLP V1スタックと同様に、必要な言語のサービスをデプロイします。以下の表に、どの言語でどのサービスが必要かを示します。service-nlp-orchestratorが常に必要であることにご注意ください。
| 言語 | コード | service-nlp-embedding インスタンス | service-nlp-classifier インスタンス |
| 万国共通 | ge-GE | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| フィンランド語-フィンランド | fi-FI | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| スウェーデン語 – スウェーデン | sv-SE | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| デンマーク語 – デンマーク | da-DK | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| ノルウェー語 – ノルウェー | nn-NO | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| ベトナム語 – ベトナム | vi-VN | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| ヒンディー語 – インド | hi-IN | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| ベンガル語 – バングラデシュ | bn-IN | service-nlp-embedding-ge | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| タミル語 – インド | ta-IN | service-nlp-embedding-ge | service-nlp-classifier-score-de および service-nlp-classifier-train-de |
| ドイツ語 – ドイツ | de-DE | service-nlp-embedding-xx | service-nlp-classifier-score-ge および service-nlp-classifier-train-ge |
| 日本語 – 日本 | ja-JP | service-nlp-embedding-xx | service-nlp-classifier-score-ja および service-nlp-classifier-train-ja |
| 韓国語 – 韓国 | ko-KR | service-nlp-embedding-xx | service-nlp-classifier-score-ko および service-nlp-classifier-train-ko |
| アラビア語 – U.A.E. | ar-AE | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| スペイン語 – スペイン | es-ES | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| フランス語 – フランス | fr-FR | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| オランダ語 – オランダ | nl-NL | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| イタリア語 – イタリア | it-IT | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| ポーランド語 – ポーランド | pl-PL | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| ポルトガル語 – ポルトガル | pt-PT | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| ポルトガル語 – ブラジル | pt-BR | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| タイ語 – タイ | th-TH | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| ロシア語 – ロシア | ru-RU | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| トルコ語 – トルコ | tr-TR | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| 中国語 – 中国 | zh-CN | service-nlp-embedding-xx | service-nlp-classifier-score-xx および service-nlp-classifier-train-xx |
| 英語 – アメリカ | en-US | service-nlp-embedding-en | service-nlp-classifier-score-en および service-nlp-classifier-train-en |
| 英語 – インド | en-IN | service-nlp-embedding-en | service-nlp-classifier-score-en および service-nlp-classifier-train-en |
| 英語 – イギリス | en-GB | service-nlp-embedding-en | service-nlp-classifier-score-en および service-nlp-classifier-train-en |
| 英語 – カナダ | en-CA | service-nlp-embedding-en | service-nlp-classifier-score-en および service-nlp-classifier-train-en |
| 英語 – オーストラリア | en-AU | service-nlp-embedding-en | service-nlp-classifier-score-en および service-nlp-classifier-train-en |
旧トレインサービスのスケールダウン
NLP V2スタックが実行されている場合、すべての新しいインテント学習ジョブはNLP V2スタックを使用します。したがって、すでにservice-nlp-train- servicesをスケールダウンすることができます。values-local.yamlでenabled: falseを設定することでこれを行うことができます。
例:
serviceNlpTrainEn:
enabled: falseメモリ制限の増加
NLP V1スタックと同様に、大規模なモデルを学習するときに、nlp-classifier-trainサービスのデフォルトのメモリ制限の問題に直面するかもしれません。デフォルトのリソース制限で始め、必要に応じてclassifier-trainサービスのメモリ制限を増やすことをお勧めします。
orchestratorとembeddingサービスは、大規模なFlowを学習するための追加メモリを必要としません。
NLP V2スタックの拡張
より多くのプロジェクトがNLP V2スタックを利用し始めると、スケーリングの必要性が生じます。最もシンプルなアプローチは、GrafanaでNLP Orchestratorのダッシュボードをモニタリングし、システム全体の待ち時間を評価し、embeddingや classifierのようなコンポーネントにスケーリングが必要かどうかを判断することです。
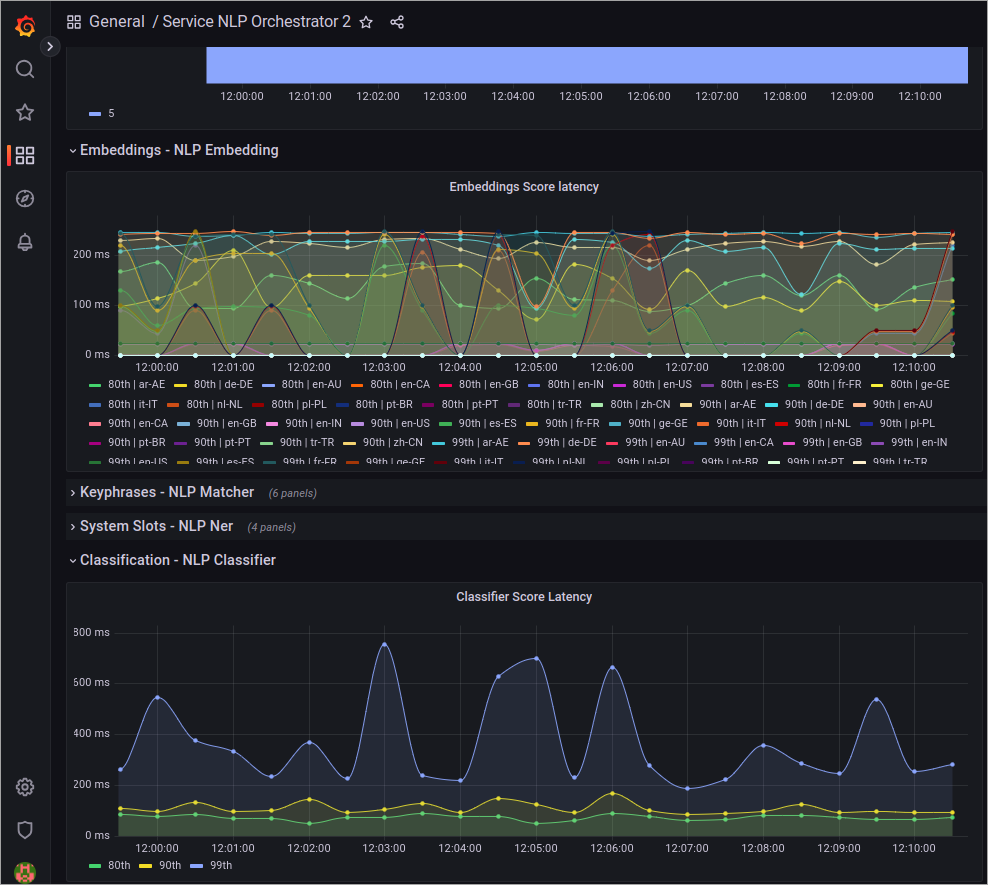
nlp-orchestrator自体のスケールアップも必要かもしれませんが、これは非常に稀なです。同じダッシュボードで、サービスのCPU負荷をモニタリングできます。1CPUに近づいたら、それに応じてこのサービスをスケールアップすることをお勧めする。
サービスが正しくデプロイされているか確認する
サービスが正しくデプロイされていることを検証するには、フローのNLUモデルを構築します。次に、service-nlp-classifier-train-<language>サービスのログを開き、サービスがモデルを学習していることをログに記録していることを確認します。
移行の実行
移行はKubernetesジョブをクラスタに適用することで実行されます。このジョブはしばらく実行され、既存のすべてのNLUモデルをNLP V2スタックに移行します。移行スクリプトを実行する前に、前章に従ってNLP V2スタックが適切に実行されていることをご確認ください。
標準の移行ジョブは、Snapshots内のモデルを含め、すべての組織と言語にわたるすべてのモデルを移行します。1つのプロジェクトにつき1つのFlowで、同時に3つのプロジェクトを移行します。
apiVersion: batch/v1
kind: Job
metadata:
name: migrate-nlp-v2-all-organisations
spec:
ttlSecondsAfterFinished: 100
template:
spec:
restartPolicy: Never
volumes:
- name: rabbitmq-connection-string
secret:
secretName: cognigy-rabbitmq
items:
- key: connection-string
path: rabbitmqConnectionString
- name: mongodb-connection-string
secret:
secretName: cognigy-service-resources
items:
- key: connection-string
path: mongodbConnectionString
- name: redis-password
secret:
secretName: cognigy-redis-password
imagePullSecrets:
- name: cognigy-registry-token
containers:
- name: nlp-v2-migrator-all
image: cognigy.azurecr.io/nlp_v2_migrator:6f28f4760e24678a27b5649555b7e0fdcdea0ebb
volumeMounts:
- name: rabbitmq-connection-string
mountPath: /var/run/secrets/rabbitmqConnectionString
subPath: rabbitmqConnectionString
- name: mongodb-connection-string
mountPath: /var/run/secrets/mongodbConnectionString
subPath: mongodbConnectionString
- name: redis-password
mountPath: /var/run/secrets/redis-password.conf
subPath: redis-password.conf
envFrom:
- configMapRef:
name: cognigy-env
env:
- name: SERVICE_RESOURCES_CONNECTION_STRING
valueFrom:
secretKeyRef:
name: cognigy-service-resources
key: connection-string
args:
- -o
- "all"
- -c
- "2"
- -cf
- "2"
- -s
- "true"どの環境を最初に移行するか?
開発環境と本番環境など複数の環境がある場合は、開発環境を最初に移行する必要があります。
移行パラメータの調整
標準の設定がご希望のモデル移行方法と一致しない場合、お客様のニーズに合わせてプロセスを調整するための様々な設定オプションをご用意しております。例えば、特定のプロジェクトを選択したり、移行を高速化したりすることができます。
そのためには、以下のパラメータを使用します:
| 値 | 説明 | 例 |
| -o | 実行する組織。組織IDのコンマ区切りのリスト。 | 63c6af010aa7a0eadd88edbd,63c6af010aa7a0eadd88edbe |
| -p | 移行するプロジェクト。プロジェクトIDのコンマ区切りのリスト。 | 63c6af010aa7a0eadd88edbd,63c6af010aa7a0eadd88edbe |
| -l | 実行するロケール。言語コードのコンマ区切りのリスト。 | en-US,de-DE,ar-AE |
| -c | 並行して移行するプロジェクトの数 | 10 |
| -cf | 並行して移行するプロジェクトごとの Flows の量 | 10 |
| -s | Snapshotsでモデルを移行するかどうか | true |
| -ct | ロケールごとにモデル数を数える。このプロセスでは移行は行われませんが、ロケールごとに存在するモデル数のリストが表示され、概要がわかります。 | true |
移行速度の向上
移行プロセスには、環境に存在するFlowsの数によってかなりの時間がかかることがあります。移行用にハードウェアを追加するオプションがある場合、または利用可能な追加容量がある場合は、NLP V2スタックをスケールアップして複数のプロジェクトを同時に移行することが可能です。これを実現するには、言語ごとに移行することをお勧めします。たとえば、すべての英語モデルの移行から始めて、次にXXコンテナグループを使用するすべてのモデルを移行する、というように行います。
サービスをスケールアップするには、以下のガイドラインを使用してください:
- 一度に20個のモデルを移行したい場合は、
nlp-classifier-train-<language>サービスの容量を増やして、同時に20個の学習ジョブを処理できるようにします。 - 20個の類別詞がある場合は、
service-nlp-embedding-<language>サービスのレプリカ数を8個に増やします。これは、所有している類別詞の総数の40%に相当します。類別詞が 20 個ある場合は、service-nlp-ner サービスのレプリカ数を 16 に増やします。 - 類別詞が 20 個ある場合は、
service-nlp-orchestratorサービスのレプリカ数を 4 に増やします。これは、service-nlp-classifierのレプリカ総数の 20% に相当します。
スケールアップした後、-cと-cfパラメータを変更することで、並列に学習するモデルの数を指定することができます。プロジェクト数が多い場合は、-cの値を大きくすることをお勧めします。逆に、Flowsの数が多いプロジェクトがいくつかある場合は、-cfの値を大きく設定することをお勧めします。
以下はXX trainグループで20のFlowsを並列にトレーニングする例です:
apiVersion: batch/v1
kind: Job
metadata:
name: migrate-nlp-v2-all-organisations
spec:
ttlSecondsAfterFinished: 100
template:
spec:
restartPolicy: Never
volumes:
- name: rabbitmq-connection-string
secret:
secretName: cognigy-rabbitmq
items:
- key: connection-string
path: rabbitmqConnectionString
- name: mongodb-connection-string
secret:
secretName: cognigy-service-resources
items:
- key: connection-string
path: mongodbConnectionString
- name: redis-password
secret:
secretName: cognigy-redis-password
imagePullSecrets:
- name: cognigy-registry-token
containers:
- name: nlp-v2-migrator-all
image: cognigy.azurecr.io/nlp_v2_migrator:6f28f4760e24678a27b5649555b7e0fdcdea0ebb
volumeMounts:
- name: rabbitmq-connection-string
mountPath: /var/run/secrets/rabbitmqConnectionString
subPath: rabbitmqConnectionString
- name: mongodb-connection-string
mountPath: /var/run/secrets/mongodbConnectionString
subPath: mongodbConnectionString
- name: redis-password
mountPath: /var/run/secrets/redis-password.conf
subPath: redis-password.conf
envFrom:
- configMapRef:
name: cognigy-env
env:
- name: SERVICE_RESOURCES_CONNECTION_STRING
valueFrom:
secretKeyRef:
name: cognigy-service-resources
key: connection-string
args:
- -o
- "all"
- -l
- "ar-AE,es-ES,fr-FR,nl-NL,it-IT,pl-PL,pt-PT,pt-BR,th-TH,ru-RU,tr-TR,zh-CN"
- -c
- "5"
- -cf
- "4"
- -s
- "true"ジョブの実行
ジョブを実行するには、kubectl apply コマンドを使用してネームスペースに適用します:
kubectl apply -n <namespace-of-cognigy-ai> <path-to-job>ジョブを実行すると、最初にV1学習グループの数とシステムに存在するプロジェクトの数が印刷されます:

移行ジョブの実行が終了したら、移行に成功したモデルの数と失敗したモデルの数を確認します。失敗したモデルがあれば、スクリプトを再実行してください。類別詞-学習ポッドのいずれかが再起動した場合は、先に進む前にメモリを増やす必要があるかもしれません:

ジョブの再実行
ジョブが失敗した場合、あるいは再度実行する必要がある場合は、いつでも安全に実行できます。ジョブは、どのモデルをまだ移行する必要があるかを認識しており、ジョブを中断したところから続行します。
古いデータのクリーンアップ
すべてのモデルの移行が完了した後、移行スクリプトで学習待ちのV1モデルがあると表示される場合があります。このような状況は、Snapshotsの削除時などに古いデータが完全にクリーンアップされていないために発生する可能性があります。
この問題を解決するには、-rフラグを付けてジョブを再実行し、データを修復します。このジョブは、他のすべての移行タスクが完了した後に実行してください。
apiVersion: batch/v1
kind: Job
metadata:
name: migrate-nlp-v2-all-organisations
spec:
ttlSecondsAfterFinished: 100
template:
spec:
restartPolicy: Never
volumes:
- name: rabbitmq-connection-string
secret:
secretName: cognigy-rabbitmq
items:
- key: connection-string
path: rabbitmqConnectionString
- name: mongodb-connection-string
secret:
secretName: cognigy-service-resources
items:
- key: connection-string
path: mongodbConnectionString
- name: redis-password
secret:
secretName: cognigy-redis-password
imagePullSecrets:
- name: cognigy-registry-token
containers:
- name: nlp-v2-migrator-all
image: cognigy.azurecr.io/nlp_v2_migrator:6f28f4760e24678a27b5649555b7e0fdcdea0ebb
volumeMounts:
- name: rabbitmq-connection-string
mountPath: /var/run/secrets/rabbitmqConnectionString
subPath: rabbitmqConnectionString
- name: mongodb-connection-string
mountPath: /var/run/secrets/mongodbConnectionString
subPath: mongodbConnectionString
- name: redis-password
mountPath: /var/run/secrets/redis-password.conf
subPath: redis-password.conf
envFrom:
- configMapRef:
name: cognigy-env
env:
- name: SERVICE_RESOURCES_CONNECTION_STRING
valueFrom:
secretKeyRef:
name: cognigy-service-resources
key: connection-string
args:
- -o
- "all"
- -s
- "true"
- -r
- "true"実行後、安全に削除できた古いモデルの数と、修復されたモデルの数が表示されます。修復されたモデルがあれば、移行を再度実行する必要があります:

移行が完了したか確認する
移行が正常に完了し、NLP V1が使用されなくなったことを確認するには、GrafanaのService NLPダッシュボードを確認します。ここで、古い NLP V1 スタックが受信した通信量をモニタリングできます。これを数日間にわたって観察することを推奨します。一貫して負荷 0 を示す場合は、V1 スタックを安全に削除できます。
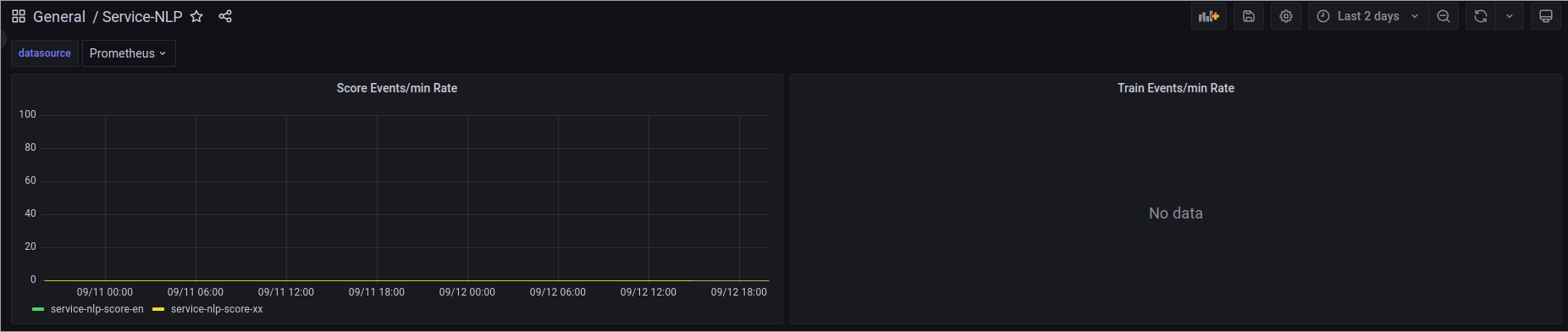
NLP V1スタックの削除
NLP V1スタックを削除するには、values-local.yamlファイルからservice-nlp-score-<lang>サービスとservice-nlp-train-<lang>サービスを削除します。
よくある質問
Q1: 移行後、既存プロジェクトに変更は必要ですか?
A1: いいえ、既存のプロジェクトに影響はありません。
Q2: 一部の Flows のみが NLP V2 に移行された場合、プロジェクトは正常に動作しますか?
A2: はい、一部のFlowsがNLP V2を使用していても、他のFlowsがNLP V1を使用していても、プロジェクトは正常に動作します。これはNLP V1のスコアコンテナがまだ稼働している環境であれば適用可能です。
Q3: NLP V2に移行したロケールと移行していないロケールがある場合、プロジェクトは正しく動作しますか?
A3: はい、一部のロケールがNLP V2に移行されていても、他のロケールが移行されていなくても、プロジェクトは正常に動作します。
Q4: NLP V2が存在する前に作成された古いSnapshotをアップロードするとどうなりますか?
A4: Snapshotをアップロードすると、そのSnapshotのすべてのNLUモデルは必要に応じてアップロードの一部としてNLP V2に移行されます。移行されたモデルの概要は[Task Menu(タスクメニュー)]でご覧いただけます。