NLUエンジンを比較検証(Watson,DialogFlow,LUISとCognigy)

優れたNLUエンジン(自然言語理解エンジン)の要件について考えてみましょう。第一に、与えられた入力の中から正しいユーザーの意図を確実に特定する能力が優れていることが求められます。同時に、「偽陽性」のミスを非常に少なくする必要があります。これは意図が全く表明されていない可能性があるにもかかわらず、与えられた意図を誤って見つけてしまうというエラーです。
今回は業界をリードする精度を誇るNLUエンジンCognigy NLUを、Microsoft LUIS、Google Dialogflow、IBM Watsonなど主要なNLUエンジンと比較した検証結果をご紹介します。
NLUエンジンを比較するには?
しかし、優れたNLUエンジンの条件は信頼性と精度だけではありません。NLUの訓練には多くの時間と労力がかかります。機械を訓練するために必要な例が少ないほど良いとされ、どの程度の例から学習を行ったかを考慮する必要があります。
NLUを評価・比較する方法としては、訓練されたモデルをそれまで見たことのない新しい入力でテストすることが挙げられます。適切なアプローチは正しい意図の分類がデータセットの一部となっている発話を無作為に選択して、ホールドアウト検証をすることです。
学習量が多いほど性能が高い
少数精鋭の学習能力を評価・識別するために、NLUをほんの一握りの例文で学習させることがあります。学習する文が少なければ少ないほど、機械の性能は低下することが予想されます。性能が実際に役立つかどうかを確認し、性能が崖のように落ちるような動作を除外して、NLUが有用な基準を維持しているかどうかを確認したいと思います。
データセットに人間のバイアスをかけずにベンチマークテストをおこなうために、CognigyではHeriott-Watt大学の研究者が編集した独立したデータセットを使用しています。
このデータセットにはホームオートメーションに関する10,000以上の発話が含まれています。研究の詳細は、論文「Benchmarking Natural Language Understanding Services for Building Conversational Agents (2019)」に掲載されています。彼らのデータはGithubで公開されています。
偏りのないベンチマークの作成
我々のテストでは、Heriott-Watt社のデータをNLUプラットフォームであるMicrosoft LUIS、Google Dialogflow、IBM Watsonに使用し、Cognigy NLUと比較しました。
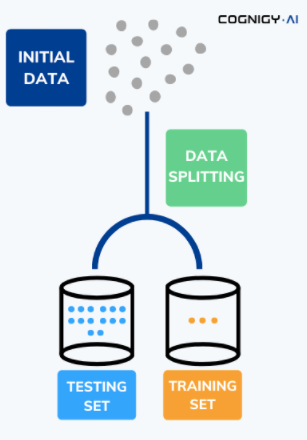
具体的には、64種類のインテント(発話意図)に対して、10個の例文をランダムに選び、それをNLUの学習に使用しました。その後、トレーニングセットに含まれていない1076の例文をテストしました。このプロセスを図に示します。
訓練文の数が異なる場合の結果を比較するために30の入力文を用いて2つ目のシナリオを構築しました。
すべての生データはGithubで公開されており、結果を再現するために使用することができます。
以下はその結果です(すべてのテストは2020年8月に実施されました)。
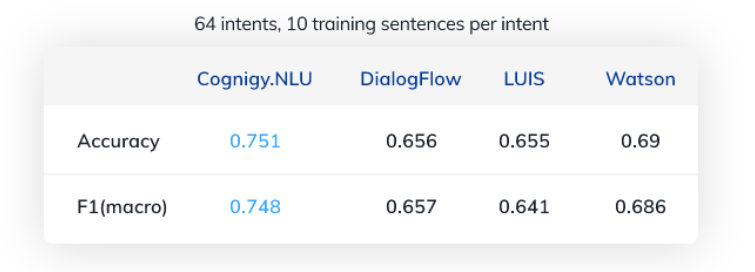
精度スコアが0.751ということは、テストセンテンスの約75%が正しい意図にマッチしたということです。
このデータセットは、最先端のNLUエンジンにとって大きな挑戦となるように意図的に設計されているため、75%というのはかなり良い結果といえます。多くの重複した難しい意図があり、ほとんどの場合、NLUは音楽などの正しいトピックをよく理解していますが、ユーザが音楽をオフにしたいのか、オンにしたいのか、曲をスキップしたいのかなどを区別することは難しいです。
これが、Cognigyがインテントによる階層構造を導入した理由の1つです。この構造では、インテントを意味的なトピックで並べることができ、このような階層的な認識の課題を解決することができます。
このプロセスを1つのインテントにつき約30の例文で繰り返し、合計5518のテスト文を作成しました。

当然のことながら、学習データが多いほど意図の認識が向上します。
しかし実際のシナリオでは、10個の学習文で達成された精度を超えるためには約3倍の数の例文を書かなければなりません。
データを拡大してみる
それでは、データセットの中から1つの具体的な例文に焦点を当てて詳細を見てみましょう。
その例文とは “are there any tornado warnings today” です。
すべてのエンジンが認識すべき真のインテントは「weather_query」、つまりユーザーが天気予報を求めていることです。
前述のNLUエンジンの個別の結果は以下のとおりです。

この表は例文から認識されたインテントとスコアを表しています。前の例のように スコアが高いほど精度が高いことを示しています。
DialogFlow、LUIS、Watsonは間違ったインテントを予測し、モデルの認識に不確実性があることを示す小さいスコアを算出しています。この例では、Cognigyのインテントの認識は正しく、スコアも比較的高いことがわかります。
舞台裏の様子
機械学習アルゴリズムの性質やランダム性には注意が必要ですが、このケースではあえて結果を解釈してみましょう。
明らかにLUISは情報が少なく”today”をカレンダーと関連づけているようです。これに対してWatsonとDialogFlowは”any traffic jam warnings today for me?”というフレーズとして解釈しています。これは「tornado(竜巻)」を無視しており、NLUをする上で何らかの形で利用されていなければなりません。
何がCognigyのパフォーマンスを左右するのか?
WatsonやDialogFlowと対照的に、CognigyのNLUは「tornado(竜巻)」を拾っています。他のNLUベンダーのAIでは説明できない能力である天気の関連付けを学習しただけではありません。この単語の重要性と文脈の中で他のインテントを表す競合信号とを比較して、この例では正しい結果を出しています。
重要なことは、このCognigy NLUが竜巻と天気などの概念が互いに離れていると認識していることです。これは、非線形性を学習するニューラルネットワークの結果であり、言葉が持つ意味をコード化して捉える能力が高いことを意味します。
Cognigy NLUを実際に使ってみたいと思いませんか?無料デモを申込み、Cognigyの最先端技術をご自身で体験してみてください。